

Machine learning models for predicting frailty in the elderly based on body composition data
-
摘要:背景 目前衰弱评估量表众多,多数指标难以客观定量。人体成分分析仪能快速获得与衰弱评估相关的定量数据,在大数据的挖掘与分析中机器学习具有一定的优势。目的 建立基于人体成分数据的机器学习模型,评价其诊断预测衰弱的价值。方法 2021年4 - 6月收集北京10个社区65岁以上老年人体检数据,以Fried衰弱表型量表作为衰弱诊断的金标准,筛选相关指标,建立随机森林、支持向量机、logistic回归和XGBoost模型,运用ROC曲线、敏感度和特异性等评价模型的预测效能。结果 共纳入558例数据进行建模分析,其中衰弱前期122例,非衰弱436例。随机森林算法筛出年龄、50 kHz全身相位角、骨骼肌质量、体脂百分比等10个重要性靠前的特征,并据此建立四个预测模型。Logistic回归模型的整体预测效能最高,ROC曲线下面积达到0.872,敏感度和特异性分别为78.38%和80.15%,预测准确率为79.76%。另外三种模型的整体效能差异不大,预测准确率均超过75%。结论 基于人体成分数据建立的logistic回归模型在预测老年人衰弱的效能上高于其他机器学习模型,且预测准确率较高,可用于衰弱的早期临床诊断。
-
关键词:
- 衰弱 /
- 机器学习 /
- 人体成分 /
- 预测模型 /
- logistic回归
Abstract:Background There are numerous frailty assessment scales, and most of the indicators are difficult to quantify objectively. The body composition analyzer can quickly obtain quantitative data related to frailty assessment, and machine learning has certain advantages in the mining and analysis of big data.Objective To establish machine learning models based on body component data and evaluate its value in diagnosis and prediction of frailty.Methods The physical examination data for the elderly over 65 years old in 10 Beijing communities were collected from April to June in 2021, and the Fried frailty phenotype scale was used as the gold standard for frailty diagnosis. Relevant indicators were screened , then random forest, support vector machine, logistic regression and XGBoost models were established to evaluate the predictive efficacy of the models using ROC curves, sensitivity and specificity.Results A total of 558 cases were included for modeling analysis, including 122 pre-frailty cases and 436 non-frailty cases. The random forest algorithm screened important features such as age, 50kHz-whole body phase angle, skeletal muscle mass, and percent body fat, and four prediction models were built based on them. The logistic regression model had the highest overall predictive efficacy with an area under the ROC curve of 0.872, sensitivity and specificity of 78.38% and 80.15%, respectively, and a predictive accuracy of 79.76%. The overall effectiveness of the other three models did not differ significantly, with prediction accuracy exceeding 75%.Conclusion The logistic regression model based on human body composition data is more effective than other machine learning models in predicting frailty in the elderly, with higher prediction accuracy, which can be used for early clinical diagnosis of frailty.-
Keywords:
- frailty /
- machine learning /
- body composition /
- predictive models /
- logistic regression
-
-
![]()
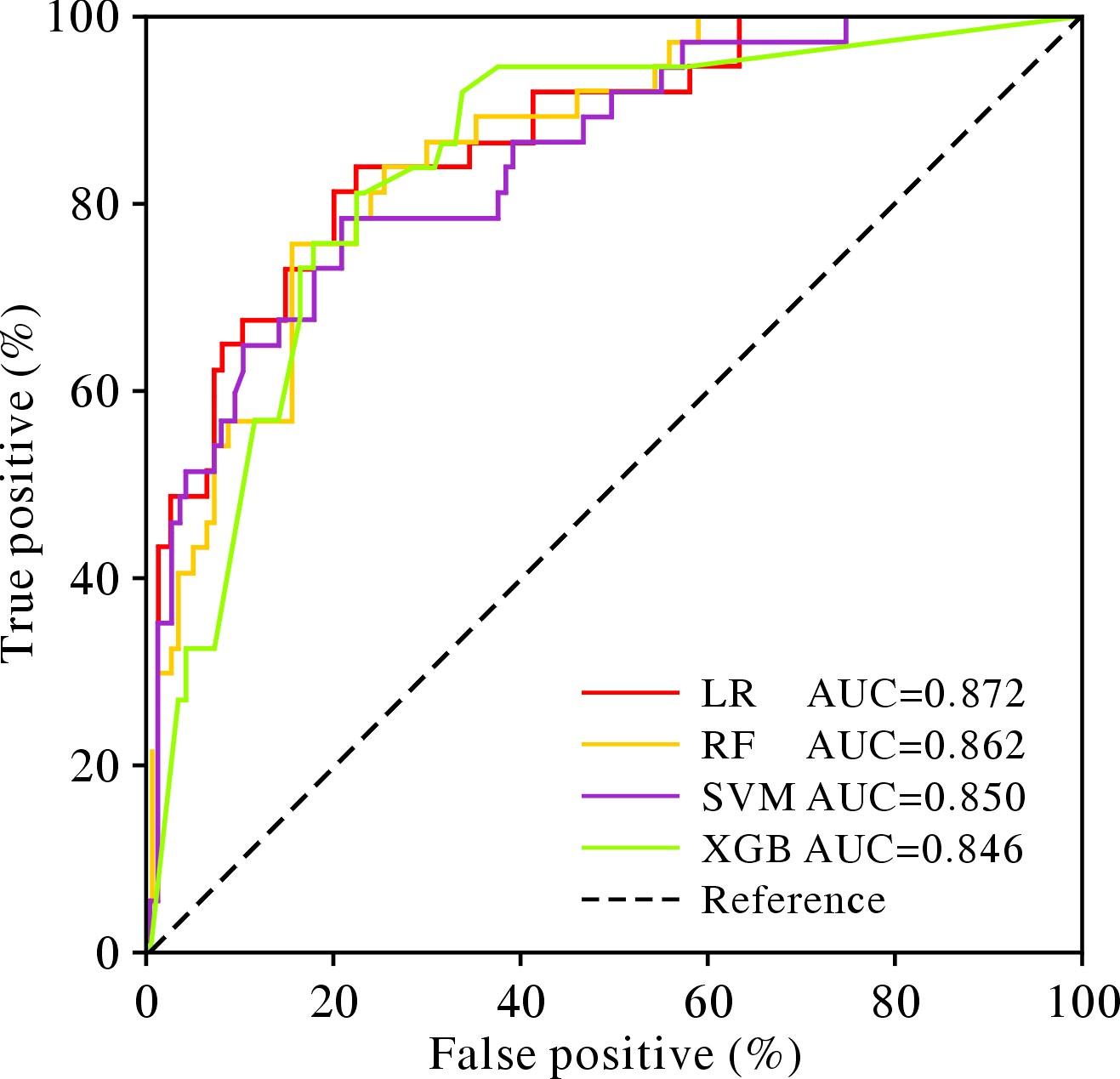
图 1 人体成分指标对预测衰弱的重要性排名
Figure 1. Importance rank of body composition features in predicting frailty
50 kHz-WBPA: 50 kHz-whole body phase angle; SMM: skeletal muscle mass; PBF: percent body fat; BCM: body cell mass; VFA: visceral fat area; BMR: basal metabolic rate; AMC: arm muscle circumference; ICW: intracellular water; TBW/FFM: total body water/fat free mass
![]()
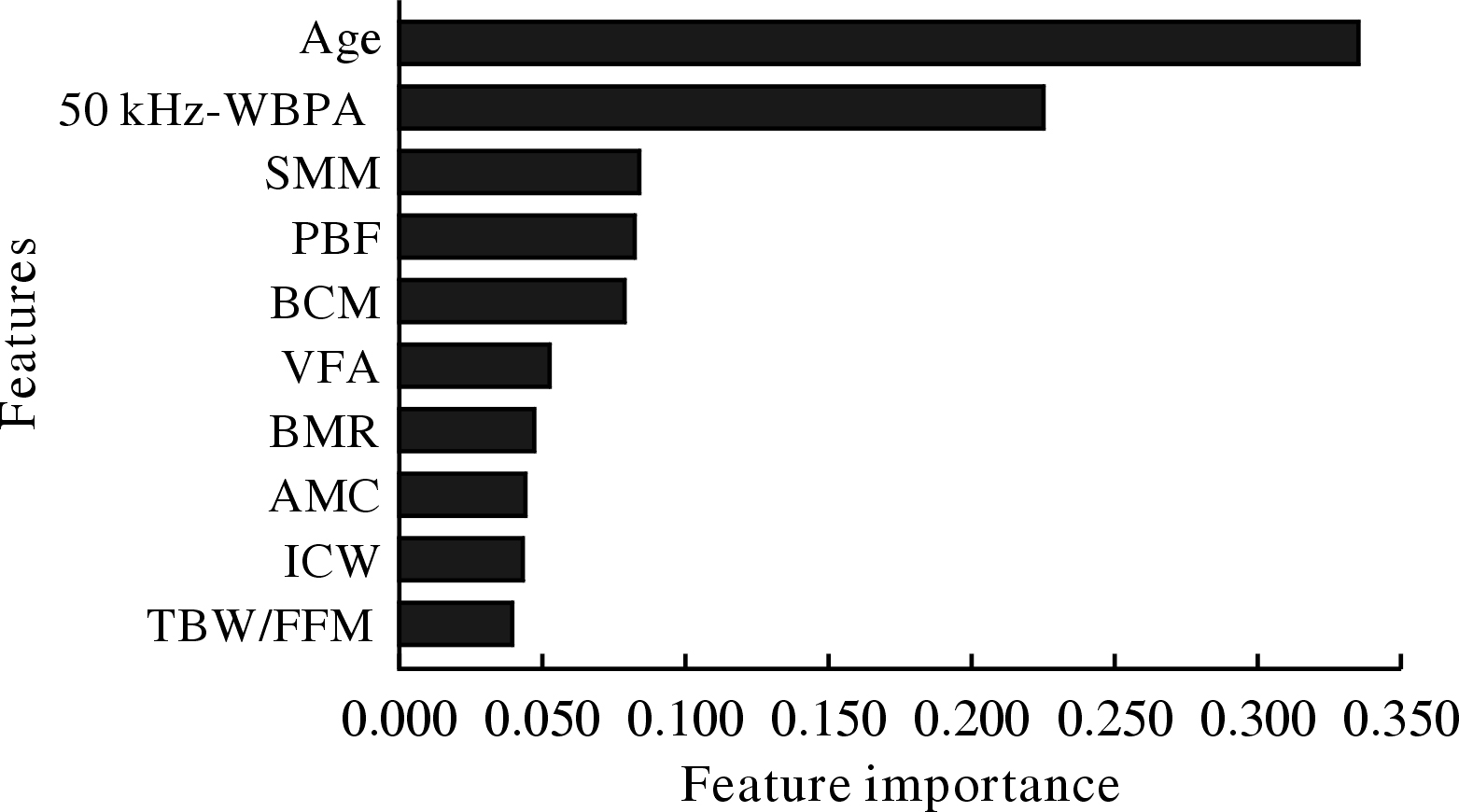
图 2 四种衰弱机器学习模型的ROC曲线
Figure 2. ROC curves of four types of frailty machine learning models
LR: logistic regression; RF: random forest; SVM: support vector machine; XGB: eXtreme Gradient Boosting
表 1 非衰弱与衰弱前期两组特征比较
Table 1 General characteristics of the two cohorts
Characteristic Non-frailty (n=436) Pre-frailty (n=122) t/H P Age/(yrs, Md[IQR]) 71(68,77) 80(74,86) 75.898 <0.001 50 kHz-WBPA/° 5.1±0.6 4.4±0.7 9.277 <0.001 SMM/(kg, Md[IQR]) 29.6(27.4,31.8) 26.9(24.9,29.2) 48.479 <0.001 PBF/% 26.9±4.9 29.1±6.1 -3.588 <0.001 BCM/kg 34.8±3.6 32.2±3.8 7.010 <0.001 VFA/cm2 103.8±36.1 94.0±27.1 -2.775 0.006 BMR/kCal 1534.8±120.4 1456.5±125.1 6.299 <0.001 AMC/cm 27.6±1.7 26.4±1.9 6.523 <0.001 ICW/L 24.3±2.5 22.5±2.6 7.000 <0.001 TBW/FFM 73.7±0.2 73.8±0.2 -6.523 <0.001 50 kHz-WBPA: 50 kHz-whole body phase angle; SMM: skeletal muscle mass; PBF: percent body fat; BCM: body cell mass; VFA: visceral fat area; BMR: basal metabolic rate; AMC: arm muscle circumference; ICW: intracellular water; TBW/FFM: total body water/fat free mass.  下载: 导出CSV
下载: 导出CSV
表 2 四种衰弱机器学习模型的预测效能
Table 2 Predictive performance of four types of frailty machine learning models
Model Probability
thresholdsSensitivity/
%Specificity/
%Accuracy/
%Random forest 0.233 75.68 77.86 77.38 Support vector machine 0.322 75.68 79.39 78.57 Logistic regression 0.230 78.38 80.15 79.76 XGBoost 0.406 68.24 79.02 76.67
下载: 导出CSV
表 3 Logistic回归模型的预测能力
Table 3 Predictive ability of the logistic regression model
Actual label Predicted label Pre-frailty Non-frailty Pre-frailty 29 8 Non-frailty 26 105
下载: 导出CSV
-
[1] Hoogendijk EO,Afilalo J,Ensrud KE,et al. Frailty: implications for clinical practice and public health[J]. Lancet,2019,394(10206): 1365-1375. doi: 10.1016/S0140-6736(19)31786-6
[2] Wang HY,Lv XZ,Du J,et al. Age- and gender-specific prevalence of frailty and its outcomes in the longevous population: the Chinese longitudinal healthy longevity study[J]. Front Med (Lausanne),2021,8: 719806.
[3] Kong LN,Lyu Q,Yao HY,et al. The prevalence of frailty among community-dwelling older adults with diabetes: a meta-analysis[J]. Int J Nurs Stud,2021,119: 103952. doi: 10.1016/j.ijnurstu.2021.103952
[4] Fried LP,Tangen CM,Walston J,et al. Frailty in older adults: evidence for a phenotype[J]. J Gerontol A Biol Sci Med Sci,2001,56(3): M146-M156. doi: 10.1093/gerona/56.3.M146
[5] Beam AL,Kohane IS. Big data and machine learning in health care[J]. JAMA,2018,319(13): 1317-1318. doi: 10.1001/jama.2017.18391
[6] 兰欣,卫荣,蔡宏伟,等. 机器学习算法在医疗领域中的应用[J]. 医疗卫生装备,2019,40(3): 93-97. [7] Hurt RT,Ebbert JO,Croghan I,et al. The comparison of segmental multifrequency bioelectrical impedance analysis and dual-energy X-ray absorptiometry for estimating fat free mass and percentage body fat in an ambulatory population[J]. JPEN J Parenter Enteral Nutr,2021,45(6): 1231-1238. doi: 10.1002/jpen.1994
[8] Liu ZY, Wei YZ, Wei LQ, et al. Frailty transitions and types of death in Chinese older adults: a population-based cohort study[J]. Clin Interv Aging, 2018, 13: 947-956.
[9] Sezgin D,O'Donovan M,Woo J,et al. Early identification of frailty: developing an international Delphi consensus on pre-frailty[J]. Arch Gerontol Geriatr,2022,99: 104586. doi: 10.1016/j.archger.2021.104586
[10] Hewitt J,Carter B,Vilches-Moraga A,et al. The effect of frailty on survival in patients with COVID-19 (COPE): a multicentre, European, observational cohort study[J]. Lancet Public Health,2020,5(8): e444-e451. doi: 10.1016/S2468-2667(20)30146-8
[11] Chen LK,Woo J,Assantachai P,et al. Asian working group for sarcopenia: 2019 consensus update on sarcopenia diagnosis and treatment[J]. J Am Med Dir Assoc,2020,21(3): 300-307.e2. doi: 10.1016/j.jamda.2019.12.012
[12] Cruz-Jentoft AJ,Bahat G,Bauer J,et al. Sarcopenia: revised European consensus on definition and diagnosis[J]. Age Ageing,2019,48(4): 601.
[13] Chen LK,Liu LK,Woo J,et al. Sarcopenia in Asia: consensus report of the Asian Working Group for Sarcopenia[J]. J Am Med Dir Assoc,2014,15(2): 95-101. doi: 10.1016/j.jamda.2013.11.025
[14] Yuan LL,Chang ML,Wang J. Abdominal obesity, body mass index and the risk of frailty in community-dwelling older adults: a systematic review and meta-analysis[J]. Age Ageing,2021,50(4): 1118-1128. doi: 10.1093/ageing/afab039
[15] Koliaki C,Liatis S,Dalamaga M,et al. Sarcopenic obesity: epidemiologic evidence, pathophysiology, and therapeutic perspectives[J]. Curr Obes Rep,2019,8(4): 458-471. doi: 10.1007/s13679-019-00359-9
[16] Hsieh TJ,Su SC,Chen CW,et al. Individualized home-based exercise and nutrition interventions improve frailty in older adults: a randomized controlled trial[J]. Int J Behav Nutr Phys Act,2019,16(1): 119. doi: 10.1186/s12966-019-0855-9
[17] Uemura K,Yamada M,Okamoto H. Association of bioimpedance phase angle and prospective Falls in older adults[J]. Geriatr Gerontol Int,2019,19(6): 503-507. doi: 10.1111/ggi.13651
[18] Garlini LM,Alves FD,Ceretta LB,et al. Phase angle and mortality: a systematic review[J]. Eur J Clin Nutr,2019,73(4): 495-508. doi: 10.1038/s41430-018-0159-1
[19] Wilhelm-Leen ER,Hall YN,Horwitz RI,et al. Phase angle, frailty and mortality in older adults[J]. J Gen Intern Med,2014,29(1): 147-154. doi: 10.1007/s11606-013-2585-z
[20] Kuo KM,Talley PC,Kuzuya M,et al. Development of a clinical support system for identifying social frailty[J]. Int J Med Inform,2019,132: 103979. doi: 10.1016/j.ijmedinf.2019.103979
[21] Ambagtsheer RC,Shafiabady N,Dent E,et al. The application of artificial intelligence (AI) techniques to identify frailty within a residential aged care administrative data set[J]. Int J Med Inform,2020,136: 104094. doi: 10.1016/j.ijmedinf.2020.104094
[22] Peng LN,Hsiao FY,Lee WJ,et al. Comparisons between hypothesis- and data-driven approaches for multimorbidity frailty index: a machine learning approach[J]. J Med Internet Res,2020,22(6): e16213. doi: 10.2196/16213
计量
- 文章访问数: 837
- HTML全文浏览量: 152
- PDF下载量: 30

